CrowdStrike停机事件教会了我们关于云安全的哪些事 媒体
CrowdStrike事件启示:加强云安全的必要策略
关键要点
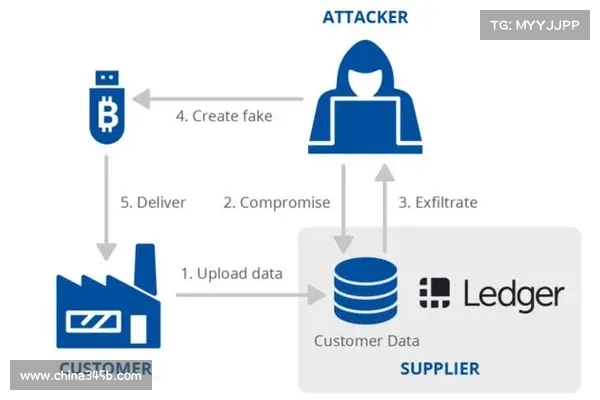
CrowdStrike的系统故障导致全球数百万台计算机崩溃,显示出云基础设施的脆弱性。事件强调了严格测试、实时监控、多环境验证和输入验证的重要性。采取多云或混合云策略以及不断的风险评估能够显著增强组织的弹性。在2024年7月19日,CrowdStrike发布的软件更新让全球的IT团队陷入了一场危机,数百万台Windows计算机出现所谓的“蓝屏死机”故障。该软件的失误导致了大规模的业务中断,不仅使航班停飞,还停止了金融交易,迫使医疗系统依赖人工流程。尽管问题源于终端安全,但这一事件为依赖云基础设施的组织提供了重要的启示。
CrowdStrike随后发布了详细的根本原因分析(RCA),探讨了事件的背后原因。然而,从云安全的角度来看,这次故障强调了几个关键原则:严格测试、强大的监控能力、多环境验证和模型输入有效性。这些组件不仅是最佳实践,更是加强云环境,防御类似中断的重要支柱。
天行加速器节点接下来,让我们深入探讨这几个方面,并探讨如何通过强化这些领域来防范云端的灾难性失败。
测试的重要性
测试是任何可靠软件发布的基石,但即使有完善的协议,某些边缘案例仍然可能未被检测到。在云环境中,风险更高:云架构必须与各种应用、服务和硬件配置进行交互。因此,严格的测试包括自动化和手动测试至关重要。在一个与生产环境紧密相似的预备环境中模拟更新可以帮助识别潜在问题,以免其影响用户。
除标准测试外,在高负载情况下对应用程序进行压力测试、故障注入测试以及各种条件下的性能评估也是云弹性的关键步骤。通过故意模拟不利条件,组织可以找出潜在的脆弱性,并增强应用程序以应对现实世界的压力。将持续测试融入DevOps管道,增加了一层安全性,从而在开发早期就能发现配置问题。持续而全面的测试确保任何新更新或补丁能够在多种环境中无缝运行,从而降低类似CrowdStrike所经历的中断风险。
实时监控与事件检测
CrowdStrike对故障的处理凸显了有效监控系统的迫切需要。在云环境中,复杂性和规模放大了风险,因此实时可见性已成为一种必要性,而非仅仅是最佳实践。尽管快速检测让CrowdStrike能够开始处理问题,但其影响已经在多个行业显现,强调了实时监控在事件响应中的重要性。
对于云从业者来说,全面的监控包括持续跟踪基础设施和应用程序性能指标。为异常行为如突然的流量激增、延迟变化或意外的资源消耗设置警报,可以帮助团队在问题升级之前捕捉潜在问题。集中式日志和警报系统是整合这些数据的必要工具,使IT团队能够可视化模式并发现异常情况。基于人工智能的监控进一步加强了这一过程,可以识别潜在的微妙模式,从而提供早期预警,帮助保持云应用程序的在线可用性。通过强有力的监控,云运营商能够主动检测、分析并应对潜在问题,最小化中断并维持服务的连续性。
多环境检查:预备环境、生产环境和沙箱
CrowdStrike事件强调了与生产环境紧密相似的预备环境的重要性。仅在受控的开发环境中进行测试会忽略生产环境中存在的复杂性和配置,尤其是对于必须在动态、互联系统中运行的云原生应用。对于在云中运营的组织而言,建立分层的部署策略至关重要。此策略从在预备环境中进行严格测试开始,然后再推向生产。
为了进一步减少风险,公司应先向小部分用户推出更新,密切监控其影响,并仅在没有出现问题的情况下扩展发布。通过在沙箱和预备环境中充分测试更新,云运营商可以确保各类设置的兼容